How I Keep My Homelab Kubernetes and GitOps Layer Simple
April 3, 2026
#homelab #kubernetes #k3s #argocd #gitops
Part 2 of a short homelab series. Part 1 explains the hardware choices, and Part 3 covers the platform apps that sit on top.
Once the hardware was in place, I had to decide how much platform I actually wanted to run on top of it.
The answer was not “as much Kubernetes as possible.” I wanted the useful parts of Kubernetes and GitOps without turning the homelab into a part-time operations project.
That is how I ended up with Ubuntu, K3s, Argo CD, and a single Nx monorepo. The stack is intentionally plain, which is exactly why it works.
Why Ubuntu And K3s
Ubuntu is the base OS because I want the host layer to be boring.
That matters more in a homelab than people like to admit. The machine already has the usual maintenance realities around firmware updates, package drift, and the occasional rebuild. I do not want to add a more unusual host stack just to make the setup feel clever.
Ubuntu is familiar, well-documented, and easy to recover. That is enough.
K3s follows the same logic. I still wanted real Kubernetes because that is the API and operating model I actually use, but I did not need a heavier distribution just to feel more serious about the cluster.
K3s is the pragmatic choice here:
- it is lightweight enough for a compact homelab
- it keeps the control plane story straightforward
- it still gives me normal Kubernetes primitives, tooling, and workflows
The important point is that I am not trying to avoid Kubernetes. I am trying to avoid unnecessary Kubernetes overhead. K3s gives me the real primitives without making the platform heavier than the workload.
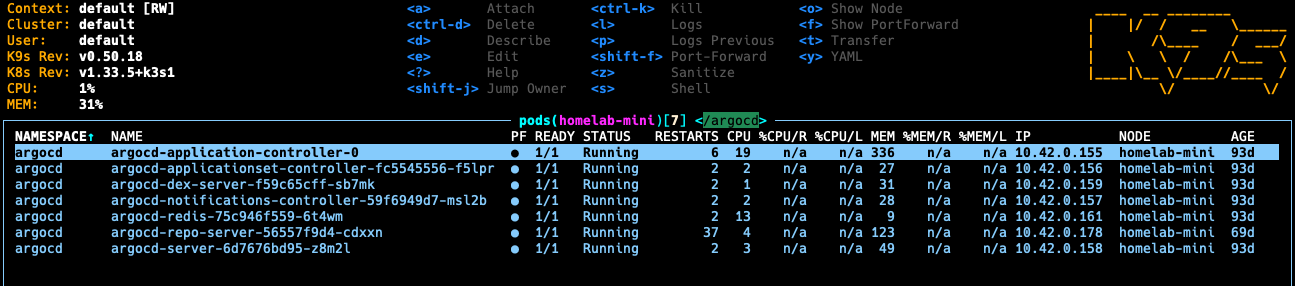
Why I Still Wanted GitOps
Even in a single-cluster setup, I still wanted GitOps.
Once the number of services grows, I do not want the desired state to live in shell history and memory. I want one answer to a practical question: what is supposed to be running here?
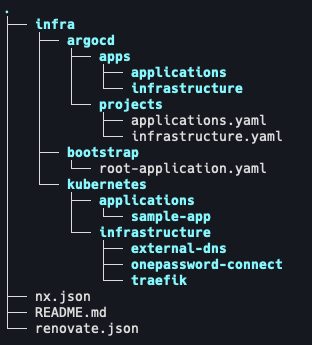
Argo CD is the right amount of structure for that. I use an app-of-apps pattern because it keeps the top-level deployment model easy to understand. In my homelab GitOps repo, there is one root application that points Argo CD at the directory containing the rest of the applications.
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: root
namespace: argocd
spec:
source:
path: infra/argocd/apps
targetRevision: HEADI like this because it is explicit without being elaborate. The structure is visible in Git, Argo CD is the reconciliation layer, and the cluster converges toward what the repo declares.
That buys me recoverability and cuts down the usual “I think I applied this manually at some point” drift. It also makes patching cleaner. Once the cluster is managed this way, I want updates to arrive as reviewable Git changes, not as something I remember only when I happen to be in the repo.
The Monorepo Shape
The repository shape is also deliberately plain.
I keep the infrastructure definitions in the same Nx-based monorepo as the application code and supporting assets. In a larger organization, that would trigger a longer conversation about ownership boundaries, blast radius, and release independence. Here, the operator model is different.
This is one cluster run by one person. I am not designing for dozens of teams with competing cadences. I am designing for one operator who wants one place to understand the system.
That makes the monorepo acceptable here for reasons that would not automatically hold elsewhere:
- the scale is small enough that repository navigation stays simple
- the ownership model is effectively one person
- infrastructure and application changes are often related in practice
- Nx still provides a useful structure without forcing artificial repo boundaries
I do not think monorepos are automatically good. In this setup, the monorepo reduces friction more than it creates it.
I am not using it to mimic a larger platform organization. I am using it because it matches the size and operating model of the homelab.
That same logic is why I like having Renovate in the loop. It keeps Helm chart versions, controller versions, and other component updates moving through the same Git path as everything else. That is better than relying on memory and occasional cleanup sessions.
Bootstrap And Dependency Ordering
Bootstrap is one of the places where GitOps conversations often get more complex than they need to be.
There is always an initial path to getting Argo CD into the cluster and pointing it at the repository. That matters once. What matters more is the steady-state model after that handoff.
Once Argo CD is managing the cluster, dependency ordering stays intentionally simple. I use sync waves as a lightweight way to say that some things need to land before others.
That is useful for the obvious cases: namespaces before workloads, storage-related pieces before consumers, shared platform services before applications that depend on them.
I like sync waves because they solve a real coordination problem without pulling the setup into a heavier orchestration model. They are not a full dependency system, and I do not need them to be. They are just a practical way to tell Argo CD that one layer should settle before another.
That fits the rest of the stack. The goal is not to eliminate every manual concern from bootstrap forever. The goal is to keep the steady-state model clear and make rebuild ordering understandable.
The Tradeoffs Of This Setup
The advantages of this design come directly from the constraints it accepts.
The cluster is single-node. The operational model is single-operator. The GitOps layer is intentionally straightforward. That keeps the system understandable, but it also means the limits are real.
If the node is down, the cluster is down. If I make a bad change, there is no team process catching it before it lands. If I ignore the setup for a while, there is no second operator carrying context forward.
Those are real tradeoffs. I accept them because the stack stays proportionate to the environment:
- one cluster means fewer moving parts to patch and debug
- one GitOps controller means one reconciliation model to understand
- one operator means decisions can optimize for clarity over ceremony
I do not feel pressure to make the system look more advanced than it is. A lot of homelab complexity comes from importing patterns that make sense at team or fleet scale and keeping them after the original reason disappears.
I would rather run a deliberately boring stack that I can rebuild, inspect, and modify confidently than a more impressive one that mostly exists to imitate production architecture out of context.
The goal is a platform shape that matches the workload, the scale, and the way I actually operate it.